直接干穿美国科技股,DeepSeek这国产模型凭啥?
- 情感
- 2025-01-28 05:37:05
- 21
专题:DeepSeek为何能震动全球AI圈
来源:差评X.PIN
马上就要过年了,差评君这几天还正忙着办年货,结果回家刚拿起手机,就被 AI 刷屏了。
如果说上次的 V3 模型,是让硅谷对中国 AI 侧目的话,那这次就直接是被掀了桌子了,他们发布了一个叫 DeepSeek-R1 的大模型,完全比得上 OpenAI-o1 那种,结果亮相以后引起的反响比上次还要大!
Meta 联合创始人看了都直呼改变历史,不惜溢美之词,还在后面的推文里跟 DeepSeek 的黑子对喷。
参投过 OpenAI 、 Databricks 、 Character.AI 等知名企业的风投大佬马克 · 安德森也对 DeepSeek-R1 一顿猛夸,说它最令人惊叹、最印象深刻,是对世界的一份深刻馈赠。
而其他 AI 爱好者和网友们也是纷纷选择用脚投票,每月几百块的 ChatGPT 拜拜了您内!

然后就跟之前小红书爆火类似, DeepSeek 的应用商店排名迅速上升,现在已经成了 APPSTORE 排名第一的软件。

不仅美国人被搞得友邦惊诧, DeepSeek 现在在国内更是红的没边。
这几天微博热搜上跟它相关的,每天都要挂好几个。
甚至不少 AI 行业的圈外人都深有感触,比如做黑神话的冯骥,也在微博上感慨良多,说这是 “ 国运级别的科技成果 ” 。

就连差评编辑部的主编老师,体验完以后都直呼好用,能拿来做培训了。

其他网友们实际体验下来,也纷纷表示这玩意确实牛逼。
不说别的,就拿跟 OpenAI-o1 对比来看,某网友让这俩分别写个脚本,要用 python 画一个红球在旋转的三角形里弹跳,结果左边 OpenAI 搞出来一坨,右边的 DeepSeek 倒是表现的相当流畅。

一句话, o1 办得了的它能办, o1 办不了的它也能办,这简直是踢馆行为,一脚踹飞了国产 AI 只能屈居人后的牌匾。
不过除了扬眉吐气以外,估计不少差友也跟差评君一样有点疑问,毕竟 DeepSeek 这么一个以前都没怎么听说过的小厂,咋突然就能支棱起来、名扬世界了呢?

在暗涌采访 DeepSeek 创始人梁文锋的报道中,咱还是找到了一部分原因,因为这是一个相当重视创新的公司。

而这种创新驱动的技术突破在这个团队内并不罕见。

不过比起单个技术点的突破,这次 R1 牛的地方却在于路径创新,甚至能改变整个 AI 领域的技术路线。

换句话说,传统大厂搞AI 就像应试教育:先给海量标注数据搞填鸭式教学( SFT ),再拿强化学习( RL )做考前突击。结果就是训练出 GPT-4o 这种 “ 别人家孩子 ” ——解题步骤工整规范,但总感觉少了点灵性。
而更要命的是,这种训练需要花大量的资源,很多时间和资金都得花在数据标注跟微调上。
但 DeepSeek 牛的地方在于,他们这个推理模型的核心全靠强化学习,完事用一个叫 GRPO 的算法给模型的回答打分,然后继续优化,这些步骤里一点 SFT 都不带用的。

于是在这种高强度的淬炼中,一个只花了 600 万美元,两个月时间锻造出来的宗门天才,出场就达到了世家大族花了几个亿资金练了几年的水平。

实际上,早在几周前, DeepSeek 团队的研究人员就用这种思路,在原先那个 V3 的基础上完全靠强化学习搞出来了一个 R1-Zero 版本
前几天 DeepSeek 放出来的的技术报告里提到, Zero 版本在训练中进化速度非常明显,很快就能跟 OpenAI-o1 掰掰手腕了,在部分测试项目中甚至还高于 o1 。
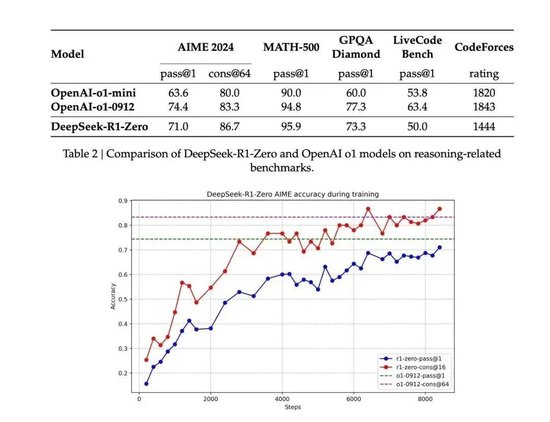
除了推理能力在明显进步,Zero 甚至在推理中表现出了主动复盘反思纠错的行为,在做题的过程中它突然就意识到自己做错了,然后开始回头演算。
官方的备注里说,大模型在这里突然用了一个拟人化的说法 aha moment ( 顿悟时刻 ),不仅 Zero“ 顿悟了 ” 了,研究人员看到这的时候也 “ 顿悟了 ” 。

当其他 AI 还在背公式时, Zero 已经学会在草稿纸上画辅助线了,这完全可以说是 AI 推理上的里程碑事件:
没有预先的数据标注、没有微调,仅仅只靠模型的强化学习,模型就可以涌现出这个程度的推理能力。
这相当于给全世界搞 AI 的人上了一课,原来还可以这么玩。。。

虽然推理能力已经被证明了,不过 Zero 的缺点也很明显。
纯强化学习养出来的 AI ,活脱脱就是个钢铁直男,模型输出的可读性较差,或者说,讲话不怎么符合人类预期。

这时候就到了 SFT 上场表演的时候了, DeepSeek 团队在 Zero 强而有力的推理基础上,又增加了一部分 SFT 训练来让模型会说人话,于是, DeepSeek-R1 堂堂诞生!
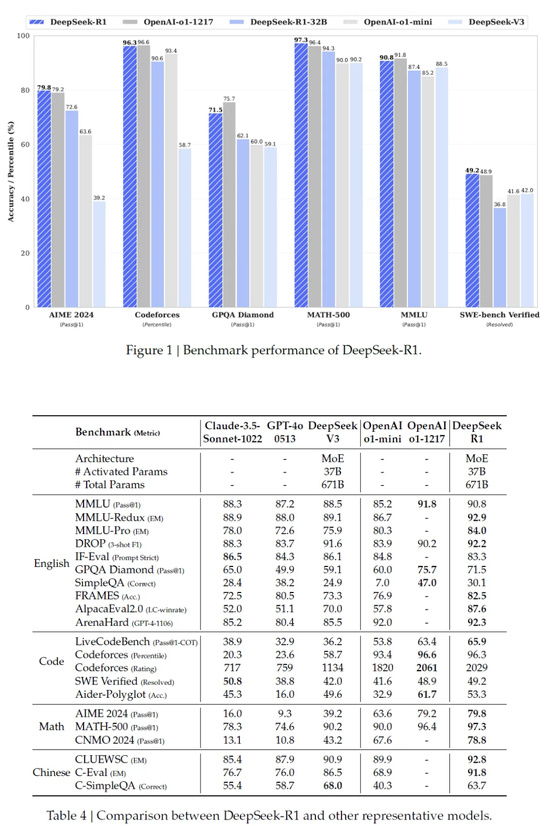
神奇的是,在 Zero 基础上经过这么一套 “ 文理双修 ” 的骚操作后,优化后的 R1 推理能力甚至还进一步提高了,还是看测试数据:

MMLU 和 AlpacaEval 2.0 综合知识测试中, R1 的胜率分别达到 90.8% 和 87.6% ,力压一众闭源大模型。
用 Yann Lecun 的话说,这波是开源的伟大胜利!这下谁还敢说开源就是落后啊。( 战术后仰 )
不过要说 R1 的成功还只是证明了开源模型的实力,那 R1 技术报告最后一部分才是最离谱的。。。

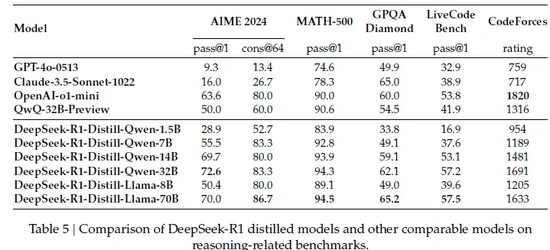
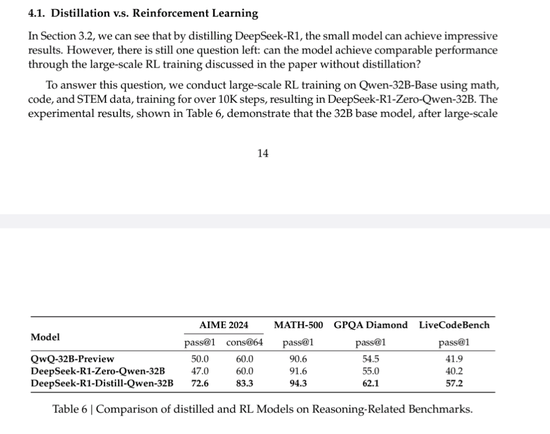
也就是说,只要把 R1 的 “ 学习笔记 ” 做成教辅资料,打包喂给其他的小模型 AI ,让它们也跟着抄作业,学会这些好学生的作业思路,结果居然能提高小模型的水平!

比如说把 R1 的错题本发给 Qwen 和 Llama 架构,结果抄完作业的 Qwen-7B 模型,在 AIME 测试中通过率达到了 55.5% ,已经赶上了参数体量大了快 5 倍的 QwQ-32B-Preview ( 50.0% );
像 70B 参数版看完了学霸笔记以后也跟打通了任督二脉似的,在 GPQA Diamond ( 65.2% )、 LiveCodeBench ( 57.5% )等任务中甚至闭都能跟闭源模型 o1-mini 掰掰手腕。
换句话说, DeepSeek 这波这不仅验证了 “ 小模型 + 好老师 ” 的技术路线,更让个人开发者也能调教出匹敌 GPT-4 的 AI 。

于是现在全球开源社区已经疯了, HuggingFace 连夜成立项目组,准备复刻整个训练流程。不少网友都说这特么的才算 Open !这个项目也被叫做 Open R1 。
也有网友算过账:用 R1 方案训练 7B 模型,成本从百万美元级直接砍到二十万级别,显卡用量比挖矿还省,这简直是真正的科技平权行为,活该它爆火!
巧合的是,跟 R1 这波爆火同时,众多赛博基建大厂们的股价开始下跌,英伟达盘前跌了 10% 以上。不少人觉得或许是因为 DeepSeek 的逆天训练成本,影响了投资人的判断。

就像梁文锋说的, “ 我们经常说中国 AI 和美国有一两年差距,但真实的 gap 是原创和模仿之差……有些探索也是逃不掉的。 ”
“ 中国AI 不可能永远处在跟随的位置。 ”
顺带一提,今天小红书上有网友被DeepSeek的性能吓到了,担心自己被AI取代,而当她向DeepSeek 表达出担忧后,它给出了这样的回答:

撰文:纳西
编辑:江江 & 面线
美编:阳光
图片、资料来源:
DeepSeek-R1 : Incentivizing Reasoning Capability in LLMs viaReinforcement Learning
暗涌 Waves :揭秘 DeepSeek : 一个极致的中国理想技术主义故事
机器学习算法与自然语言处理:大模型 SFT 的 100 个关键点
深度学习与 NLP ,新智元, X 等,部分图源网络
相关文章



热门文章

随着马赫萨·阿米尼逝世两周年的临近,伊朗妇女不再戴头巾
2024-12-16
24年香港正版资料免费公开,2024全年免费资科大全,3网通用:3DM60.01.16
2024-12-1849图库-资料中心,最准一肖精准,移动\电信\联通 通用版:主页版v061.660
2024-12-18246天天天彩天好彩资料大全二四,红姐统一图库图免费第一,移动\电信\联通 通用版:3DM82.61.61
2024-12-18王浩辞去浙江省省长职务
2024-12-1949图库在线预览,二四天天正版资料免费大全,移动\电信\联通 通用版:手机版743.340
2024-12-18
市场专家洞察:4种加密货币准备在2025年牛市中占据主导地位
2024-12-16
Pembina Gas Infrastructure签署4亿美元协议,从Veren购买中游资产
2024-12-16
有话要说...